A Multilanguage Pokémon TCG Database with Cards Pictures and most of the informations contained on the cards. You can find out more about TCGdex at [https://www.tcgdex.net](https://www.tcgdex.net) or on [Discord](https://discord.gg/NehYTAhsZE).
Auto-generated OpenAPI schema
# Introduction We have prepared a set of APIs for quick start to integrate telematics SDK that powers mobile telematics inside 3rd party mobile applications. * [CONTACT US](https://telematicssdk.com) * [SANDBOX](https://userdatahub.com) * [DEV.PORTAL](https://docs.telematicssdk.com) * [DEMO APP](https://raxeltelematics.com/telematics-app) # Overview Datamotion provides telematics infrastructure for mobile applications. Telematics SDK turns any smartphone into telematics data gathering device to collect Location, driving and behavior data. API services unlocks power of your mobile application There are 3 groups of methods: * 1 - user management * 2 - statistics for mobile app * 3 - statistics for back-end(s) in certain cases you will need SNS or any other notification services. read more [here](https://docs.telematicssdk.com/platform-features/sns) # Possible architecture There are three common schemes that are used by our clients. These schemes can be combined * Collect, Process, Store (required: 1&2) * Collect, Process (required: 1& sns) * Collect (required 1&sns) ## Collect, Process, Store 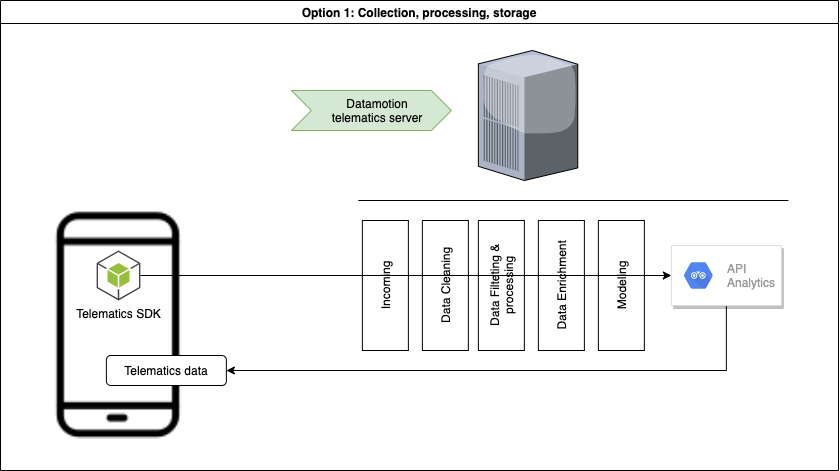 ## Collect, Process 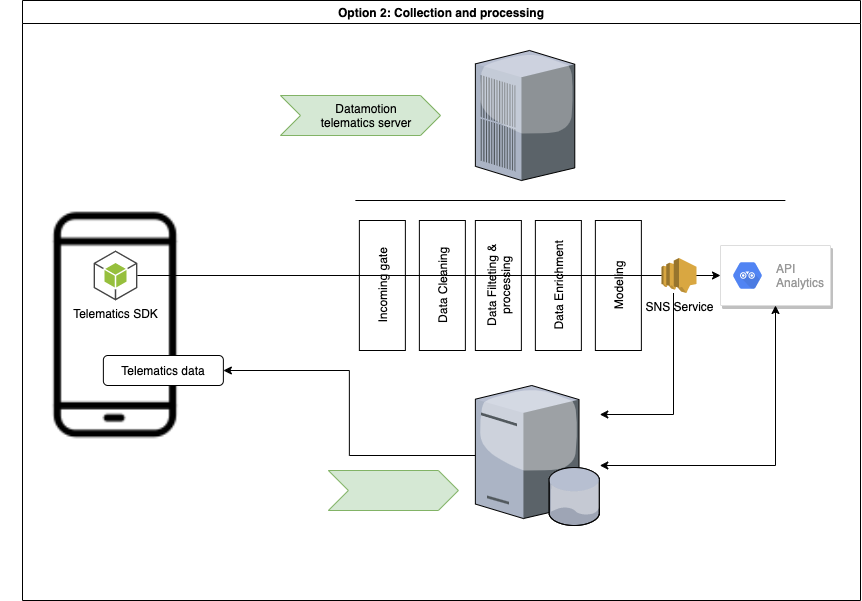 ## Collect 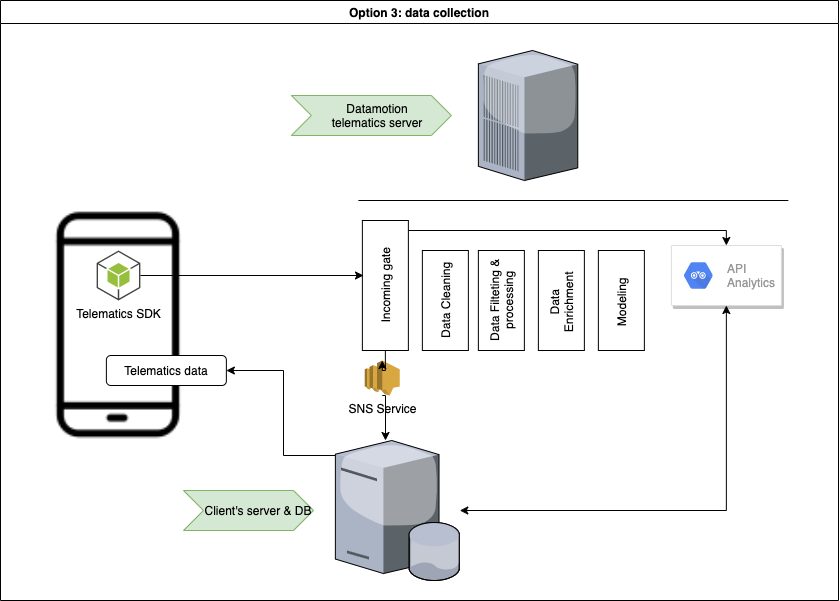 ***  # Common use-cases: * Safe and efficient driving * Usage-based insurance * Safe driving assessment * Driver assessment * Trip log * Geo-analysis * Accident monitoring * Driving engagements * Location based services * Realtime Tracking and beyond # How to start * Register a [SANDBOX ACCOUNT](https://userdatahub.com) * Get [CREDENTIALS](https://docs.userdatahub.com/sandbox/credentials) * Follow the guide from [DEVELOPER POERTAL](https://docs.telematicssdk.com) # Authentication To create a user on datamotion platform, you require to use InstanceID and InstanceKEY. You can get it in Datahub -> management -> user-service credentials Once you create a user, you will get Device token, JWT token and refresh token. then, you will use it for APIs
SIP trunking, SMS, MMS, Call Control and Telephony Data Services.
The current api version is v3.4
The api methods listed below can be called directly from this page to test the output. You might set the api_key to pre-authenticate all requests on this page (this will work if your secret is blank).
API endpoint URL: http://{apiName}.text2data.com/v3/ {method}
The api can be consumed directly or using our SDK. Our Excel Add-In and Google Sheets Add-on are also using this api to process the data.
Our unified API brings together data across all modes of transport into a single RESTful API. This API provides access to the most highly requested realtime and status infomation across all the modes of transport, in a single and consistent way. Access to the developer documentation is available at https://api.tfl.gov.uk
# Overview Information and statistics about FIRST Robotics Competition teams and events. # Authentication All endpoints require an Auth Key to be passed in the header `X-TBA-Auth-Key`. If you do not have an auth key yet, you can obtain one from your [Account Page](/account).
Icons for Everything
The SMS Works provides a low-cost, reliable SMS API for developers. Pay only for delivered texts, all failed messages are refunded.
API v3 targets v2 functionality with a few minor additions. The API is accessible via https://api.thetvdb.com and provides the following REST endpoints in JSON format.
How to use this API documentation
----------------
You may browse the API routes without authentication, but if you wish to send requests to the API and see response data, then you must authenticate.
1. Obtain a JWT token by `POST`ing to the `/login` route in the `Authentication` section with your API key and credentials.
1. Paste the JWT token from the response into the "JWT Token" field at the top of the page and click the 'Add Token' button.
You will now be able to use the remaining routes to send requests to the API and get a response.
Language Selection
----------------
Language selection is done via the `Accept-Language` header. At the moment, you may only pass one language abbreviation in the header at a time. Valid language abbreviations can be found at the `/languages` route..
Authentication
----------------
Authentication to use the API is similar to the How-to section above. Users must `POST` to the `/login` route with their API key and credentials in the following format in order to obtain a JWT token.
`{"apikey":"APIKEY","username":"USERNAME","userkey":"USERKEY"}`
Note that the username and key are ONLY required for the `/user` routes. The user's key is labled `Account Identifier` in the account section of the main site.
The token is then used in all subsequent requests by providing it in the `Authorization` header. The header will look like: `Authorization: Bearer
The public API open to the users. [Read the docs and learn more.](https://threatjammer.com/docs). ## General information ### Description Threat Jammer supports two end-user REST APIs: the User API and the Report API. The end-user uses the User API to interact with the different databases, heuristics, and machine learning processes. Devices use the Report API to interact with Threat Jammer. This document will explain how to use the User API and interact with the different services, create a token, interpret the quota information, and create the HTTP request to interact with the User API. ### Authentication The API is protected by a **Bearer authentication** schema. **Bearer authentication** (also called **token authentication**) is an HTTP authentication scheme that involves security tokens called bearer tokens. It is used to authenticate the user. All the different endpoints expect a `Bearer` token in the `Authorization` header. Example: ``` curl -X 'GET' 'https://dublin.api.threatjammer.com/test' -H 'accept: application/json' -H 'Authorization: Bearer YOUR_API_KEY' ``` You can obtain a token after registering on the [ThreatJammer.com](https://threatjammer.com) website for free. ### Region specific tokens All the `Bearer` tokens contain information about the authorized region. The developers have to use a token created for the region they want to use. A token used in a different region will return a `401 Unauthorized` error. ### Global errors The API will return the following permanent errors: - a `401 Unauthorized` error if the token is not valid, or does not belong to the region. - a `401 Unauthorized` error if the token does not exist. - a `401 Unauthorized` error if the token is malformed. - a `403 Forbidden` error if the subscription level is not enough. Some endpoints are only available for paid subscription levels. And these temporary errors: - a `429 Too Many Requests` error if the quota is exceeded (see below). ### Quota limits **Every request to the User API will consume one (1) quota point.** The API has two rate limiting processes: - a quota limit of **5000** requests per month for the `FREE` account. The limit is reset every month. - a quota limit of **10** requests per minute for the `FREE` account. The limit is reset every minute and implements a sliding window mechanism.
Use the Ticketmaster Commerce API to look up available offers and products on various Ticketmaster platforms for North America markets. For formal partnerships and relationships, selected offers and products can be carted and transacted on through the cart, delivery, payment and purchase APIs – These APIs require approved access from Ticketmaster.
The Ticketmaster Discovery API allows you to search for events, attractions, or venues.
Publish API
Paste a Long URL link to shorten it
Tisane is a natural language processing library, providing: * standard NLP functionality * special functions for detection of problematic or abusive content * low-level NLP like morphological analysis and tokenization of no-space languages (Chinese, Japanese, Thai) Tisane has monolithic architecture. All the functions are exposed using the same language models and the same analysis process invoked using the [POST /parse](#561264c5-6dbe-4bde-aba3-7defe837989f) method. Other methods in the API are either wrappers based on the process, helper methods, or allow inspection of the language models. The current section of the documentation describes the two structures used in the parsing & transformation methods. # Getting Started This guide describes how to setup your Tisane account. The steps you need to complete are as follows: * Step 1 – Create an Account * Step 2 – Save Your API Key * Step 3 – Integrate the API ## Step 1 – Create an Account Navigate to [Sign up to Tisane API](https://tisane.ai/signup/). The free Community Plan allows up to 50,000 requests but comes with a limitation of 10 requests per minute. ## Step 2 - Save Your API Key You will need the API key to make requests. Open your [Developer Profile](https://tisane.ai/developer/) to find your API keys. ## Step 3 - Integrate with the API In summary, the POST /parse method has 3 attributes: *content*, *language*, and *settings*. All 3 attributes are mandatory. For example: `{"language": "en", "content": "hello", "settings": {}}` Read on for more info on the [response](#response-reference) and the [settings](#settings-reference) specs. The method doc pages contain snippets of code for your favorite languages and platforms. # Response Reference The response of the [POST /parse](#561264c5-6dbe-4bde-aba3-7defe837989f) method contains several sections displayed or hidden according to the [settings](#settings-reference) provided. The common attributes are: * `text` (string) - the original input * `reduced_output` (boolean) - if the input is too big, and verbose information like the lexical chunk was requested, the verbose information will not be generated, and this flag will be set to `true` and returned as part of the response * `sentiment` (floating-point number) - a number in range -1 to 1 indicating the document-level sentiment. Only shown when `document_sentiment` [setting](#settings-reference) is set to `true`. * `signal2noise` (floating-point number) - a signal to noise ranking of the text, in relation to the array of concepts specified in the `relevant` [setting](#settings-reference). Only shown when the `relevant` setting exists. ## Abusive or Problematic Content The `abuse` section is an array of detected instances of content that may violate some terms of use. **NOTE**: the terms of use in online communities may vary, and so it is up to the administrators to determine whether the content is indeed abusive. For instance, it makes no sense to restrict sexual advances in a dating community, or censor profanities when it's accepted in the bulk of the community. The section exists if instances of abuse are detected and the `abuse` [setting](#settings-reference) is either omitted or set to `true`. Every instance contains the following attributes: * `offset` (unsigned integer) - zero-based offset where the instance starts * `length` (unsigned integer) - length of the content * `sentence_index` (unsigned integer) - zero-based index of the sentence containing the instance * `text` (string) - fragment of text containing the instance (only included if the `snippets` [setting](#settings-reference) is set to `true`) * `tags` (array of strings) - when exists, provides additional detail about the abuse. For instance, if the fragment is classified as an attempt to sell hard drugs, one of the tags will be *hard_drug*. * `type` (string) - the type of the abuse * `severity` (string) - how severe the abuse is. The levels of severity are `low`, `medium`, `high`, and `extreme` * `explanation` (string) - when available, provides rationale for the annotation; set the `explain` setting to `true` to enable. The currently supported types are: * `personal_attack` - an insult / attack on the addressee, e.g. an instance of cyberbullying. Please note that an attack on a post or a point, or just negative sentiment is not the same as an insult. The line may be blurred at times. See [our Knowledge Base for more information](http://tisane.ai/knowledgebase/how-do-i-detect-personal-attacks/). * `bigotry` - hate speech aimed at one of the [protected classes](https://en.wikipedia.org/wiki/Protected_group). The hate speech detected is not just racial slurs, but, generally, hostile statements aimed at the group as a whole * `profanity` - profane language, regardless of the intent * `sexual_advances` - welcome or unwelcome attempts to gain some sort of sexual favor or gratification * `criminal_activity` - attempts to sell or procure restricted items, criminal services, issuing death threats, and so on * `external_contact` - attempts to establish contact or payment via external means of communication, e.g. phone, email, instant messaging (may violate the rules in certain communities, e.g. gig economy portals, e-commerce portals) * `adult_only` - activities restricted for minors (e.g. consumption of alcohol) * `mental_issues` - content indicative of suicidal thoughts or depression * `allegation` - claimed knowledge or accusation of a misconduct (not necessarily crime) * `provocation` - content likely to provoke an individual or a group * `disturbing` - graphic descriptions that may disturb readers * `no_meaningful_content` - unparseable gibberish without apparent meaning * `data_leak` - private data like passwords, ID numbers, etc. * `spam` - (RESERVED) spam content * `generic` - undefined ## Sentiment Analysis The `sentiment_expressions` section is an array of detected fragments indicating the attitude towards aspects or entities. The section exists if sentiment is detected and the `sentiment` [setting](#settings-reference) is either omitted or set to `true`. Every instance contains the following attributes: * `offset` (unsigned integer) - zero-based offset where the instance starts * `length` (unsigned integer) - length of the content * `sentence_index` (unsigned integer) - zero-based index of the sentence containing the instance * `text` (string) - fragment of text containing the instance (only included if the `snippets` setting is set to `true`) * `polarity` (string) - whether the attitude is `positive`, `negative`, or `mixed`. Additionally, there is a `default` sentiment used for cases when the entire snippet has been pre-classified. For instance, if a review is split into two portions, *What did you like?* and *What did you not like?*, and the reviewer replies briefly, e.g. *The quiet. The service*, the utterance itself has no sentiment value. When the calling application is aware of the intended sentiment, the *default* sentiment simply provides the targets / aspects, which will be then added the sentiment externally. * `targets` (array of strings) - when available, provides set of aspects and/or entities which are the targets of the sentiment. For instance, when the utterance is, *The breakfast was yummy but the staff is unfriendly*, the targets for the two sentiment expressions are `meal` and `staff`. Named entities may also be targets of the sentiment. * `reasons` (array of strings) - when available, provides reasons for the sentiment. In the example utterance above (*The breakfast was yummy but the staff is unfriendly*), the `reasons` array for the `staff` is `["unfriendly"]`, while the `reasons` array for `meal` is `["tasty"]`. * `explanation` (string) - when available, provides rationale for the sentiment; set the `explain` setting to `true` to enable. Example: ``` json "sentiment_expressions": [ { "sentence_index": 0, "offset": 0, "length": 32, "polarity": "positive", "reasons": ["close"], "targets": ["location"] }, { "sentence_index": 0, "offset": 38, "length": 29, "polarity": "negative", "reasons": ["disrespectful"], "targets": ["staff"] } ] ``` ## Entities The `entities_summary` section is an array of named entity objects detected in the text. The section exists if named entities are detected and the `entities` [setting](#settings-reference) is either omitted or set to `true`. Every entity contains the following attributes: * `name` (string) - the most complete name of the entity in the text of all the mentions * `ref_lemma` (string) - when available, the dictionary form of the entity in the reference language (English) regardless of the input language * `type` (string) - a string or an array of strings specifying the type of the entity, such as `person`, `organization`, `numeric`, `amount_of_money`, `place`. Certain entities, like countries, may have several types (because a country is both a `place` and an `organization`). * `subtype` (string) - a string indicating the subtype of the entity * `mentions` (array of objects) - a set of instances where the entity was mentioned in the text Every mention contains the following attributes: * `offset` (unsigned integer) - zero-based offset where the instance starts * `length` (unsigned integer) - length of the content * `sentence_index` (unsigned integer) - zero-based index of the sentence containing the instance * `text` (string) - fragment of text containing the instance (only included if the `snippets` setting is set to `true`) Example: ``` json "entities_summary": [ { "type": "person", "name": "John Smith", "ref_lemma": "John Smith", "mentions": [ { "sentence_index": 0, "offset": 0, "length": 10 } ] } , { "type": [ "organization", "place" ] , "name": "UK", "ref_lemma": "U.K.", "mentions": [ { "sentence_index": 0, "offset": 40, "length": 2 } ] } ] ``` ### Entity Types and Subtypes The currently supported entity types are: * `person`, with optional subtypes: `fictional_character`, `important_person`, `spiritual_being` * `organization` (note that a country is both an organization and a place) * `place` * `time_range` * `date` * `time` * `hashtag` * `email` * `amount_of_money` * `phone` phone number, either domestic or international, in a variety of formats * `role` (a social role, e.g. position in an organization) * `software` * `website` (URL), with an optional subtype: `tor` for Onion links; note that web services may also have the `software` type assigned * `weight` * `bank_account` only IBAN format is supported; subtypes: `iban` * `credit_card`, with optional subtypes: `visa`, `mastercard`, `american_express`, `diners_club`, `discovery`, `jcb`, `unionpay` * `coordinates` (GPS coordinates) * `credential`, with optional subtypes: `md5`, `sha-1` * `crypto`, with optional subtypes: `bitcoin`, `ethereum`, `monero`, `monero_payment_id`, `litecoin`, `dash` * `event` * `file` only Windows pathnames are supported; subtypes: `windows`, `facebook` (for images downloaded from Facebook) * `flight_code` * `identifier` * `ip_address`, subtypes: `v4`, `v6` * `mac_address` * `numeric` (an unclassified numeric entity) * `username` ## Topics The `topics` section is an array of topics (subjects, domains, themes in other terms) detected in the text. The section exists if topics are detected and the `topics` [setting](#settings-reference) is either omitted or set to `true`. By default, a topic is a string. If `topic_stats` [setting](#settings-reference) is set to `true`, then every entry in the array contains: * `topic` (string) - the topic itself * `coverage` (floating-point number) - a number between 0 and 1, indicating the ratio between the number of sentences where the topic is detected to the total number of sentences ## Long-Term Memory The `memory` section contains optional context to pass to the `settings` in subsequent messages in the same conversation thread. See [Context and Long-Term Memory](#context-and-long-term-memory) for more details. ## Low-Level: Sentences, Phrases, and Words Tisane allows obtaining more in-depth data, specifically: * sentences and their corrected form, if a misspelling was detected * lexical chunks and their grammatical and stylistic features * parse trees and phrases The `sentence_list` section is generated if the `words` or the `parses` [setting](#settings-reference) is set to `true`. Every sentence structure in the list contains: * `offset` (unsigned integer) - zero-based offset where the sentence starts * `length` (unsigned integer) - length of the sentence * `text` (string) - the sentence itself * `corrected_text` (string) - if a misspelling was detected and the spellchecking is active, contains the automatically corrected text * `words` (array of structures) - if `words` [setting](#settings-reference) is set to `true`, generates extended information about every lexical chunk. (The term "word" is used for the sake of simplicity, however, it may not be linguistically correct to equate lexical chunks with words.) * `parse_tree` (object) - if `parses` [setting](#settings-reference) is set to `true`, generates information about the parse tree and the phrases detected in the sentence. * `nbest_parses` (array of parse objects) if `parses` [setting](#settings-reference) is set to `true` and `deterministic` [setting](#settings-reference) is set to `false`, generates information about the parse trees that were deemed close enough to the best one but not the best. ### Words Every lexical chunk ("word") structure in the `words` array contains: * `type` (string) - the type of the element: `punctuation` for punctuation marks, `numeral` for numerals, or `word` for everything else * `text` (string) - the text * `offset` (unsigned integer) - zero-based offset where the element starts * `length` (unsigned integer) - length of the element * `corrected_text` (string) - if a misspelling is detected, the corrected form * `lettercase` (string) - the original letter case: `upper`, `capitalized`, or `mixed`. If lowercase or no case, the attribute is omitted. * `stopword` (boolean) - determines whether the word is a [stopword](https://en.wikipedia.org/wiki/Stop_words) * `grammar` (array of strings or structures) - generates the list of grammar features associated with the `word`. If the `feature_standard` setting is defined as `native`, then every feature is an object containing a numeral (`index`) and a string (`value`). Otherwise, every feature is a plain string #### Advanced For lexical words only: * `role` (string) - semantic role, like `agent` or `patient`. Note that in passive voice, the semantic roles are reverse to the syntactic roles. E.g. in a sentence like *The car was driven by David*, *car* is the patient, and *David* is the agent. * `numeric_value` (floating-point number) - the numeric value, if the chunk has a value associated with it * `family` (integer number) - the ID of the family associated with the disambiguated word-sense of the lexical chunk * `definition` (string) - the definition of the family, if the `fetch_definitions` [setting](#settings-reference) is set to `true` * `lexeme` (integer number) - the ID of the lexeme entry associated with the disambiguated word-sense of the lexical chunk * `nondictionary_pattern` (integer number) - the ID of a non-dictionary pattern that matched, if the word was not in the language model but was classified by the nondictionary heuristics * `style` (array of strings or structures) - generates the list of style features associated with the `word`. Only if the `feature_standard` setting is set to `native` or `description` * `semantics` (array of strings or structures) - generates the list of semantic features associated with the `word`. Only if the `feature_standard` setting is set to `native` or `description` * `segmentation` (structure) - generates info about the selected segmentation, if there are several possibilities to segment the current lexical chunk and the `deterministic` setting is set to `false`. A segmentation is simply an array of `word` structures. * `other_segmentations` (array of structures) - generates info about the segmentations deemed incorrect during the disambiguation process. Every entry has the same structure as the `segmentation` structure. * `nbest_senses` (array of structures) - when the `deterministic` setting is set to `false`, generates a set of hypotheses that were deemed incorrect by the disambiguation process. Every hypothesis contains the following attributes: `grammar`, `style`, and `semantics`, identical in structure to their counterparts above; and `senses`, an array of word-senses associated with every hypothesis. Every sense has a `family`, which is an ID of the associated family; and, if the `fetch_definitions` setting is set to `true`, `definition` and `ref_lemma` of that family. For punctuation marks only: * `id` (integer number) - the ID of the punctuation mark * `behavior` (string) - the behavior code of the punctuation mark. Values: `sentenceTerminator`, `genericComma`, `bracketStart`, `bracketEnd`, `scopeDelimiter`, `hyphen`, `quoteStart`, `quoteEnd`, `listComma` (for East-Asian enumeration commas like *、*) ### Parse Trees and Phrases Every parse tree, or more accurately, parse forest, is a collection of phrases, hierarchically linked to each other. At the top level of the parse, there is an array of root phrases under the `phrases` element and the numeric `id` associated with it. Every phrase may have children phrases. Every phrase has the following attributes: * `type` (string) - a [Penn treebank phrase tag](http://nliblog.com/wiki/knowledge-base-2/nlp-1-natural-language-processing/penn-treebank/penn-treebank-phrase-level-tags/) denoting the type of the phrase, e.g. *S*, *VP*, *NP*, etc. * `family` (integer number) - an ID of the phrase family * `offset` (unsigned integer) - a zero-based offset where the phrase starts * `length` (unsigned integer) - the span of the phrase * `role` (string) - the semantic role of the phrase, if any, analogous to that of the words * `text` (string) - the phrase text, where the phrase members are delimited by the vertical bar character. Children phrases are enclosed in brackets. E.g., *driven|by|David* or *(The|car)|was|(driven|by|David)*. Example: ``` json "parse_tree": { "id": 4, "phrases": [ { "type": "S", "family": 1451, "offset": 0, "length": 27, "text": "(The|car)|was|(driven|by|David)", "children": [ { "type": "NP", "family": 1081, "offset": 0, "length": 7, "text": "The|car", "role": "patient" }, { "type": "VP", "family": 1172, "offset": 12, "length": 15, "text": "driven|by|David", "role": "verb" } ] } ``` ### Context-Aware Spelling Correction Tisane supports automatic, context-aware spelling correction. Whether it's a misspelling or a purported obfuscation, Tisane attempts to deduce the intended meaning, if the language model does not recognize the word. When or if it's found, Tisane adds the `corrected_text` attribute to the word (if the words / lexical chunks are returned) and the sentence (if the sentence text is generated). Sentence-level `corrected_text` is displayed if `words` or `parses` are set to *true*. Note that as Tisane works with large dictionaries, you may need to exclude more esoteric terms by using the `min_generic_frequency` setting. Note that **the invocation of spell-checking does not depend on whether the sentences and the words sections are generated in the output**. The spellchecking can be disabled by setting `disable_spellcheck` to `true`. Another option is to enable the spellchecking for lowercase words only, thus excluding potential proper nouns in languages that support capitalization; to avoid spell-checking capitalized and uppercase words, set `lowercase_spellcheck_only` to `true`. # Settings Reference The purpose of the settings structure is to: * provide cues about the content being sent to improve the results * customize the output and select sections to be shown * define standards and formats in use * define and calculate the signal to noise ranking All settings are optional. To leave all settings to default, simply provide an empty object (`{}`). ## Content Cues and Instructions `format` (string) - the format of the content. Some policies will be applied depending on the format. Certain logic in the underlying language models may require the content to be of a certain format (e.g. logic applied on the reviews may seek for sentiment more aggressively). The default format is empty / undefined. The format values are: * `review` - a review of a product or a service or any other review. Normally, the underlying language models will seek for sentiment expressions more aggressively in reviews. * `dialogue` - a comment or a post which is a part of a dialogue. An example of a logic more specific to a dialogue is name calling. A single word like "idiot" would not be a personal attack in any other format, but it is certainly a personal attack when part of a dialogue. * `shortpost` - a microblogging post, e.g. a tweet. * `longform` - a long post or an article. * `proofread` - a post which was proofread. In the proofread posts, the spellchecking is switched off. * `alias` - a nickname in an online community. * `search` - a search query. Search queries may not always be grammatically correct. Certain topics and items, that we may otherwise let pass, are tagged with the `search` format. `disable_spellcheck` (boolean) - determines whether the automatic spellchecking is to be disabled. Default: `false`. `lowercase_spellcheck_only` (boolean) - determines whether the automatic spellchecking is only to be applied to words in lowercase. Default: `false` `min_generic_frequency` (int) - allows excluding more esoteric terms; the valid values are 0 thru 10. `subscope` (boolean) - enables sub-scope parsing, for scenarios like hashtag, URL parsing, and obfuscated content (e.g. *ihateyou*). Default: `false`. `lang_detect_segmentation_regex` (string) - allows defining custom language detection fragment boundaries. For example, if multiple languages may be used in different sentences in the same text, you may want to define the regex as: `(([\r\n]|[.!?][ ]))` . `domain_factors` (set of pairs made of strings and numbers) - provides a session-scope cues for the domains of discourse. This is a powerful tool that allows tailoring the result based on the use case. The format is, family ID of the domain as a key and the multiplication factor as a value (e.g. *"12345": 5.0*). For example, when processing text looking for criminal activity, we may want to set domains relevant to drugs, firearms, crime, higher: `"domain_factors": {"31058": 5.0, "45220": 5.0, "14112": 5.0, "14509": 3.0, "28309": 5.0, "43220": 5.0, "34581": 5.0}`. The same device can be used to eliminate noise coming from domains we know are irrelevant by setting the factor to a value lower than 1. `when` (date string, format YYYY-MM-DD) - indicates when the utterance was uttered. (TO BE IMPLEMENTED) The purpose is to prune word senses that were not available at a particular point in time. For example, the words *troll*, *mail*, and *post* had nothing to do with the Internet 300 years ago because there was no Internet, and so in a text that was written hundreds of years ago, we should ignore the word senses that emerged only recently. ## Output Customization `abuse` (boolean) - output instances of abusive content (default: `true`) `sentiment` (boolean) - output sentiment-bearing snippets (default: `true`) `document_sentiment` (boolean) - output document-level sentiment (default: `false`) `entities` (boolean) - output entities (default: `true`) `topics` (boolean) - output topics (default: `true`), with two more relevant settings: * `topic_stats` (boolean) - include coverage statistics in the topic output (default: `false`). When set, the topic is an object containing the attributes `topic` (string) and `coverage` (floating-point number). The coverage indicates a share of sentences touching the topic among all the sentences. * `optimize_topics` (boolean) - if `true`, the less specific topics are removed if they are parts of the more specific topics. For example, when the topic is `cryptocurrency`, the optimization removes `finance`. `words` (boolean) - output the lexical chunks / words for every sentence (default: `false`). In languages without white spaces (Chinese, Japanese, Thai), the tokens are tokenized words. In languages with compounds (e.g. German, Dutch, Norwegian), the compounds are split. `fetch_definitions` (boolean) - include definitions of the words in the output (default: `false`). Only relevant when the `words` setting is `true` `parses` (boolean) - output parse forests of phrases `deterministic` (boolean) - whether the n-best senses and n-best parses are to be output in addition to the detected sense. If `true`, only the detected sense will be output. Default: `true` `snippets` (boolean) - include the text snippets in the abuse, sentiment, and entities sections (default: `false`) `explain` (boolean) - if `true`, a reasoning for the abuse and sentiment snippets is provided when possible (see the `explanation` attribute) ## Standards and Formats `feature_standard` (string) - determines the standard used to output the features (grammar, style, semantics) in the response object. The standards we support are: * `ud`: [Universal Dependencies tags](https://universaldependencies.org/u/pos/) (default) * `penn`: [Penn treebank tags](https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html) * `native`: Tisane native feature codes * `description`: Tisane native feature descriptions Only the native Tisane standards (codes and descriptions) support style and semantic features. `topic_standard` (string) - determines the standard used to output the topics in the response object. The standards we support are: * `iptc_code` - IPTC topic taxonomy code * `iptc_description` - IPTC topic taxonomy description * `iab_code` - IAB topic taxonomy code * `iab_description` - IAB topic taxonomy description * `native` - Tisane domain description, coming from the family description (default) `sentiment_analysis_type` (string) - the type of the sentiment analysis strategy. The values are: * `products_and_services` - most common sentiment analysis of products and services * `entity` - sentiment analysis with entities as targets * `creative_content_review` - reviews of creative content (RESERVED) * `political_essay` - political essays (RESERVED) ## Context and Long-Term Memory Human understanding of language is not a simple "sliding window" with scope limited to a sentence. Language is accompanied by gestures, visuals, and knowledge of the previous communication. Sometimes, code-words may be used to conceal the words' original meaning. When detecting abuse, a name of an ethnicity or a religious group may be not offensive, but when superimposed over a picture of an ape or a pig, it is meant of offend. When translating from a language without gender distinctions in verbs (like English) to a language with distinctions (like Russian or Hebrew), there is no way to know from an utterance alone if the speaker is female. When a scammer is collecting details piecemeal over a series of utterances, knowledge of previous utterances is needed to take action. Tisane's Memory module allows pre-initializing the analysis, as well as reassigning meanings, and more. The module is made of three simple components that are flexible enough for a variety of tasks: ### Reassignments Reassignments define the attributes to set based on other attributes. This allows to: * assign gender to 1st or 2nd person verbs, generating accurate translations * overwrite original meaning of a group of words with all their inflected forms to analyze code-words and secret language * add an additional feature or a hypernym to a family and more, within a scope of a call. The `assign` section is an array of structures defining: * `if` - conditions to match: * `regex` - a regular expression (RE2 syntax) * `family` - a family ID * `features` - a list of feature values. A feature is a structure with an `index` and a `value`. For example: `{"index":1, "value":"NOUN"}`. * `hypernym` - a family ID of a hypernym * `then` - attributes to assign * `family` - a family ID * `features` - a list of feature values. A feature is a structure with an `index` and a `value`. For example: `{"index":1, "value":"NOUN"}`. * `hypernym` - a family ID of a hypernym Examples: * the speaker is female: \`"assign":\[{"if":{"features":\[{"index":9,"value":"1"}\]},"then":{"features":\[{"index":5,"value":"F"}\]}}\] * assume that a mention of a container refers to an illegal item: \`"assign":\[{"if":{"family":26888},"then":{"hypernym":123078}}\] ### Flags An array of flag structures that add some context. A flag is a structure with an `index` and a `value`. For example: `{"index":36, "value":"WFH"}`. Aside from the flags returned in the `memory` section of the response, these flags can be set: * `{"index":36, "value":"PEBD"}` (agents_of_bad_things) - the context is about a bad player or an agent responsible for bad things * `{"index":36, "value":"BADANML"}` (bad_animal) - the context is an animal that symbolizes bad qualities (e.g. pig, ape, snake, etc.) * `{"index":36, "value":"BULKMSG"}` (bulk_message) - the message was sent in bulk * `{"index":36, "value":"DETHR"}` (death_related) - the context is something related to death * `{"index":36, "value":"EARNMUCH"}` (make_money) - the context is related to making money * `{"index":36, "value":"IDEP"}` (my_departure) - the author of the text mentioned departing * `{"index":36, "value":"SECO"}` (sexually_conservative) - any attempt to exchange photos or anything that may be either sexual or non-sexual is to be deemed sexual * `{"index":36, "value":"TRPA"}` (trusted_party) - the author of the text claims to be a trusted party (e.g. a relative or a spouse) * `{"index":36, "value":"WSTE"}` (waste) - the context is about waste, organic or inorganic * `{"index":36, "value":"WOPR"}` (won_prize) - prize or money winning was mentioned or implied * `{"index":36, "value":"WFH"}` (work_from_home) - work from home was mentioned * `{"index":5, "value":"ORG"}` (organization) - an organization was mentioned * `{"index":5, "value":"ROLE"}` (role) - a role or a position was mentioned ### Antecedents The section contains structures to be used in coreference resolution. The attributes are: * `family` - the family ID of the antecedent * `features` - the list of features. Every feature is a structure with an `index` and a `value`. For example: `{"index":36, "value":"WFH"}`. ## Signal to Noise Ranking When we're studying a bunch of posts commenting on an issue or an article, we may want to prioritize the ones more relevant to the topic, and containing more reason and logic than emotion. This is what the signal to noise ranking is meant to achieve. The signal to noise ranking is made of two parts: 1. Determine the most relevant concepts. This part may be omitted, depending on the use case scenario (e.g. we want to track posts most relevant to a particular set of issues). 2. Rank the actual post in relevance to these concepts. To determine the most relevant concepts, we need to analyze the headline or the article itself. The headline is usually enough. We need two additional settings: * `keyword_features` (an object of strings with string values) - determines the features to look for in a word. When such a feature is found, the family ID is added to the set of potentially relevant family IDs. * `stop_hypernyms` (an array of integers) - if a potentially relevant family ID has a hypernym listed in this setting, it will not be considered. For example, we extracted a set of nouns from the headline, but we may not be interested in abstractions or feelings. E.g. from a headline like *Fear and Loathing in Las Vegas* we want *Las Vegas* only. Optional. If `keyword_features` is provided in the settings, the response will have a special attribute, `relevant`, containing a set of family IDs. At the second stage, when ranking the actual posts or comments for relevance, this array is to be supplied among the settings. The ranking is boosted when the domain, the hypernyms, or the families related to those in the `relevant` array are mentioned, when negative and positive sentiment is linked to aspects, and penalized when the negativity is not linked to aspects, or abuse of any kind is found. The latter consideration may be disabled, e.g. when we are looking for specific criminal content. When the `abuse_not_noise` parameter is specified and set to `true`, the abuse is not penalized by the ranking calculations. To sum it up, in order to calculate the signal to noise ranking: 1. Analyze the headline with `keyword_features` and, optionally, `stop_hypernyms` in the settings. Obtain the `relevant` attribute. 2. When analyzing the posts or the comments, specify the `relevant` attribute obtained in step 1.
Web API for TL mobile and web app
Please see usage policies on tokenjay.app